

RAG (Retrieval-Augmented Generation) is an AI technique that combines information retrieval with text generation to produce more accurate and contextually relevant responses.
Why do I need RAG?
You need RAG when you want a large language model to answer questions based on your own data, and the information it wasn’t trained on. This helps reduce hallucinations and enables the model to provide responses grounded in your specific content. We will go into details of hallucination and grounding in the upcoming posts. But for now, you want to talk to your documents, and RAG is here to help.
How do I train the LLM to use my data?
To implement RAG, you typically go through a few core steps:
First, you break your documents (knowledge base) into smaller parts, known as chunks. The way you chunk your content can significantly impact the quality of your results. There are several strategies for chunking, each with its own pros and cons. We’ll explore those in future posts. For now, let’s use the default CharacterTextSplitter for chunking.
Next, you convert each chunk into a vector embedding, a numerical format that captures the semantic meaning of the text.
These embeddings are then stored in a vector database (or in-memory store for smaller setups). When a user submits a query, it’s also converted into an embedding and compared against the stored ones to retrieve the most relevant chunks.
Those retrieved chunks & the context are sent along with the query to a large language model, which then generates a response that’s grounded in your data.
While vector databases are the go-to for scalability and speed, simpler RAG implementations can run entirely in memory if the dataset is small.
Follow these steps, and you’ve got yourself a working RAG pipeline!
Sample RAG Application
The following code shows how you can write a simple RAG application.
Create a folder called test_rag, go into that folder, and run the following command to create a new Python virtual environment.
1
uv venv venv
Once the virtual environment is created, activate the environment using the command:
In Windows:
1
.\venv\Scripts\activate
In Linux:
1
source venv/bin/activate
Once the virtual environment is activated, install the required Python libraries:
1
pip install langchain openai tiktoken
The following program uses OpenAI, so you need an API KEY. Once you have the key, add that to your environment:
1
export OPENAI_API_KEY=your-api-key-here
You can also place that OPENAI_API_KEY in a .env file and load it in the Python program.
The following program uses langchain, which is a popular framework to develop AI applications. Copy the code and paste it inside a file rag.py inside that test_rag folder.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import CharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.document_loaders import Document
import os
# Optional: set API key via environment variable
os.environ["OPENAI_API_KEY"] = "your-api-key-here"
# Hardcoded document (your "knowledge base")
text = """
LangChain is a framework for developing applications powered by language models.
It enables retrieval-augmented generation (RAG), conversational agents, and more.
You can build custom chains, integrate with tools, and manage memory easily.
LangChain supports various LLMs and vector stores.
"""
# 1. Split text into chunks
text_splitter = CharacterTextSplitter(chunk_size=200, chunk_overlap=0)
chunks = text_splitter.split_text(text)
documents = [Document(page_content=chunk) for chunk in chunks]
# 2. Create embeddings + in-memory vector store (FAISS)
embedding_model = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embedding_model)
# 3. Set up a retriever and connect it to an LLM
retriever = vectorstore.as_retriever()
llm = ChatOpenAI(temperature=0)
rag_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True
)
# 4. Ask a question!
query = "What is LangChain used for?"
result = rag_chain(query)
# 5. Print result
print("Answer:", result["result"])
Finally, run the code using the following command:
1
python rag.py
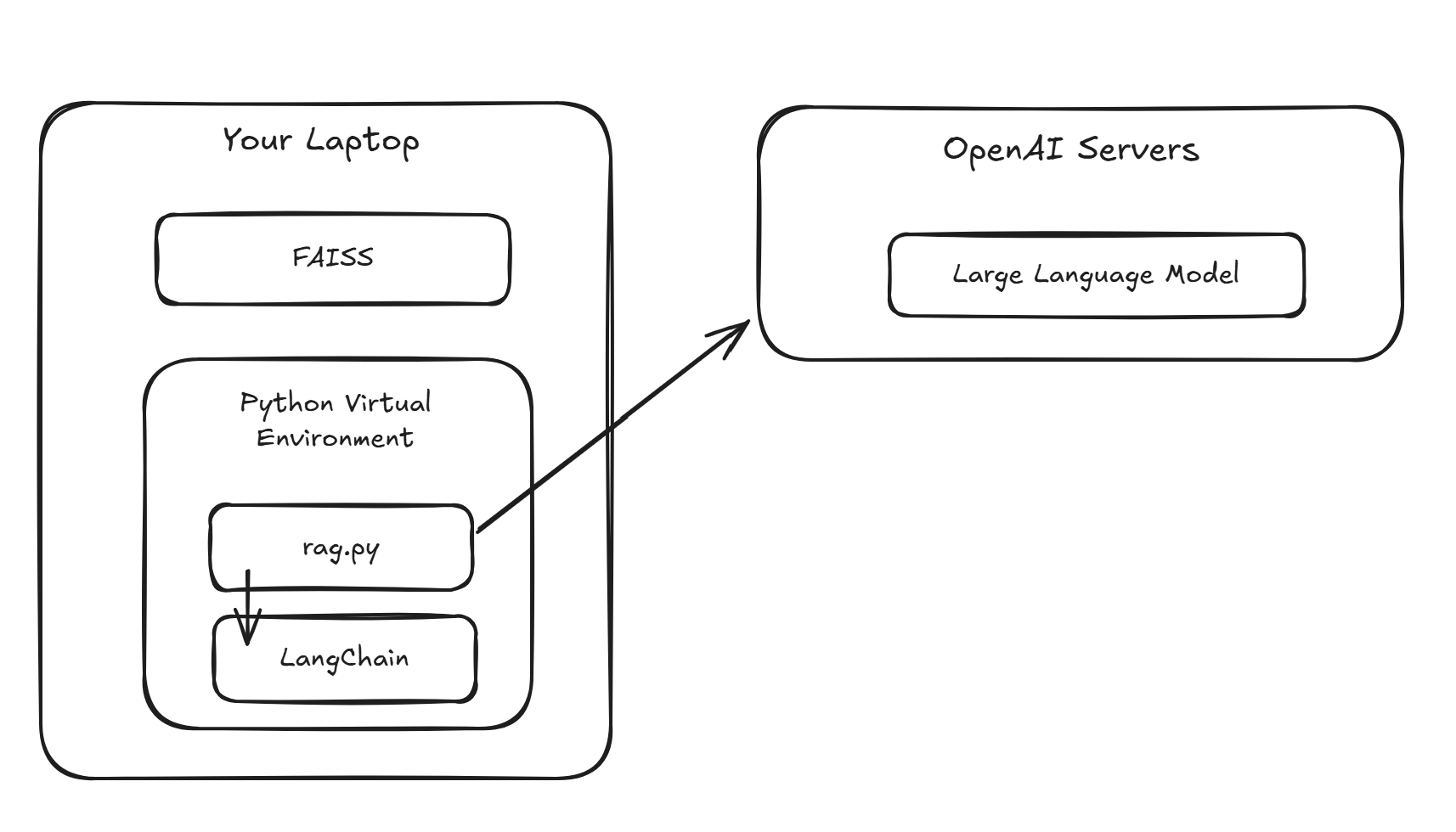
The program above uses FAISS as the in-memory vector database to store the embeddings, uses a hard-coded text as your document, and it creates chunks and embeddings based on that text and lets you interact with the data.
The following high-level architecture diagram shows how your application (running locally) connects to OpenAI servers, authenticates using the API_KEY, sends your documents collection, and asks for a relevant response.
In the upcoming posts, we will learn a bit more advanced RAG concepts like chunking strategies, model parameters, reranking, etc. Hope this gives you a basic understanding of what RAG is and how you can build your own RAG-based applications for your personal use. In the future, we will also explore options on how you can run large language models on your personal computer (given you have good hardware that can run open-source models) and have this application run completely on your local machine without needing OpenAI API keys.
Good luck!